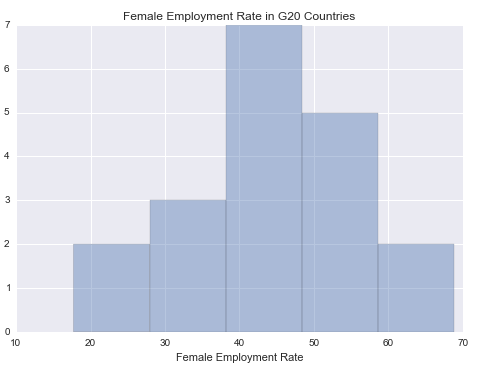
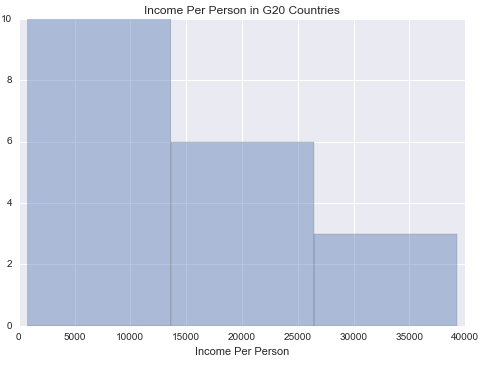
I am using the Gapminder
dataset and my response variable is FemaleEmploymentRate
and Explanatory variable is Polityscore.
My hypothesis is that female employment rate is related to
polity score. Polity score captures the
regime authority spectrum on a 21-point scale ranging from -10 (hereditary
monarchy) to +10 (consolidated democracy). Polity score is the category
variable with 21 possible categories.
I have chosen to look at just the G20 countries for my
research. The data set is managed accordingly.
Code
"""
Created on Fri Oct 30 06:50:52 2015
@author: Abhishek
"""
import pandas
import numpy
import statsmodels.formula.api as smf
import statsmodels.stats.multicomp as multi
data = pandas.read_csv('gapminder.csv', low_memory=False)
pandas.set_option('display.float_format', lambda x: '%f'%x)
data['femaleemployrate'] = data['femaleemployrate'].convert_objects(convert_numeric=True)
data['incomeperperson'] = data['incomeperperson'].convert_objects(convert_numeric=True)
data['polityscore'] = data['polityscore'].convert_objects(convert_numeric=True)
dataG20Copy = data[(data['country'] == 'Argentina') |
(data['country'] == 'Australia') |
(data['country'] == 'Brazil') |
(data['country'] == 'Canada') |
(data['country'] == 'China') |
(data['country'] == 'France') |
(data['country'] == 'Germany') |
(data['country'] == 'India') |
(data['country'] == 'Indonesia') |
(data['country'] == 'Italy') |
(data['country'] == 'Japan') |
(data['country'] == 'Mexico') |
(data['country'] == 'Russia') |
(data['country'] == 'Saudi Arabia') |
(data['country'] == 'South Africa') |
(data['country'] == 'Korea, Rep.') |
(data['country'] == 'Turkey') |
(data['country'] == 'United Kingdom') |
(data['country'] == 'United States')]
# Not always necessary but can eliminate a setting with copy warning that is displayed
dataG20 = dataG20Copy.copy()
subPolity = dataG20[['femaleemployrate','polityscore']].dropna()
modelPolity = smf.ols(formula='femaleemployrate ~ C(polityscore)',data=subPolity).fit()
print(modelPolity.summary())
mean = subPolity.groupby('polityscore').mean()
print(mean)
sd = subPolity.groupby('polityscore').std()
print(sd)
mc1 = multi.MultiComparison(subPolity['femaleemployrate'],subPolity['polityscore'])
res1 = mc1.tukeyhsd()
print(res1.summary())
OLS Test Results

Group Means
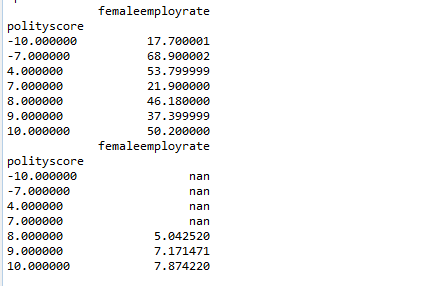
Looking at the p value, we see that there is good chance that the null hypothesis can be rejected. Post Hoc test results will determine for which categories null hypothesis can be rejected.
Turn Key HSD / Post Hoc Test Results

The Groups for which reject column is True in the above results are groups where NULL Hypothesis can be safely rejected.
In conclusion, it is evident that Female Employment Rate is indeed dependent on Polity score of a G20 country.